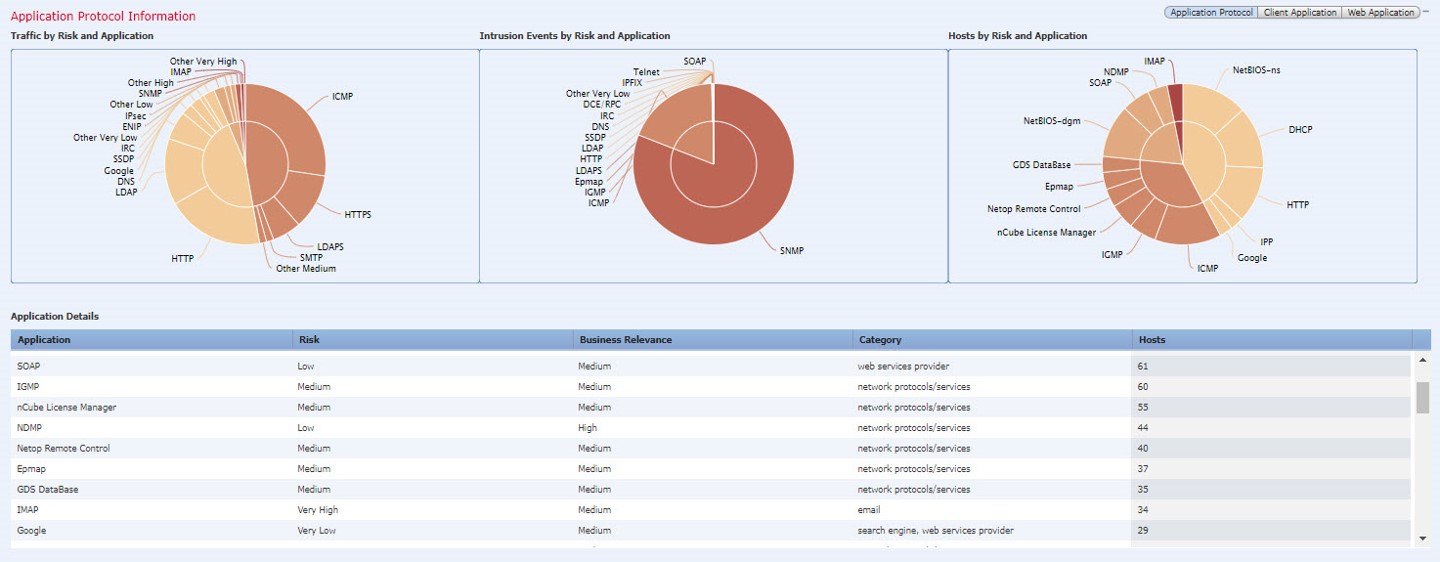
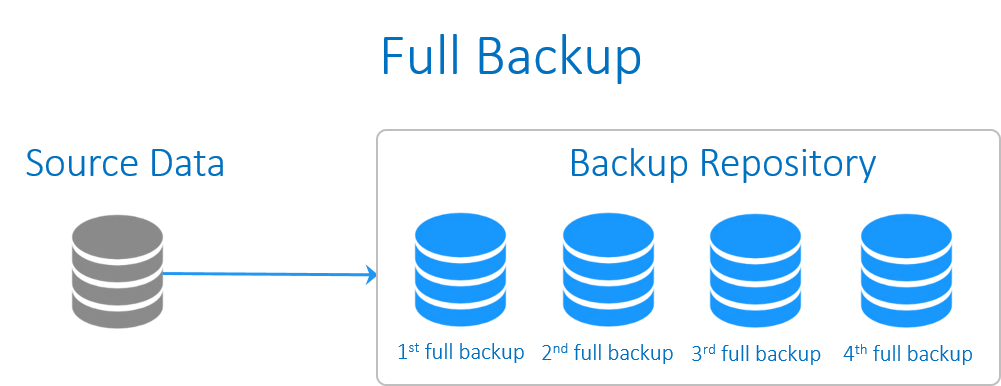
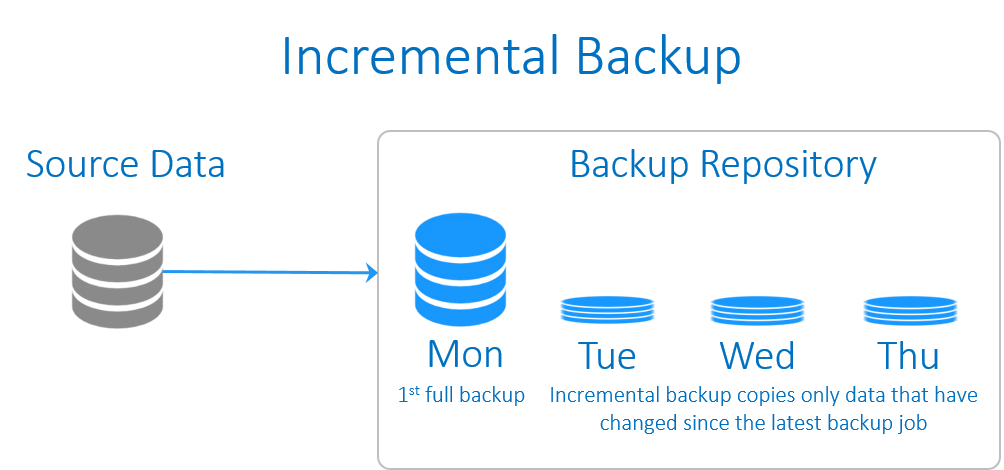
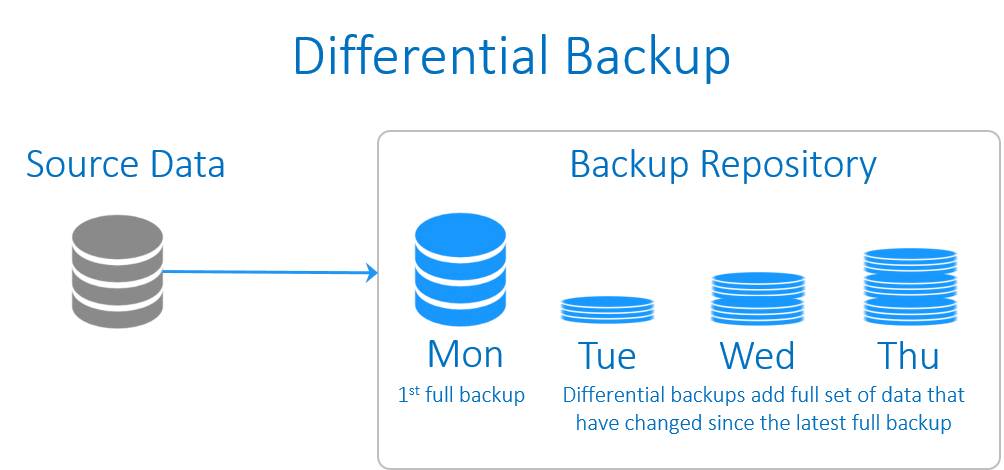
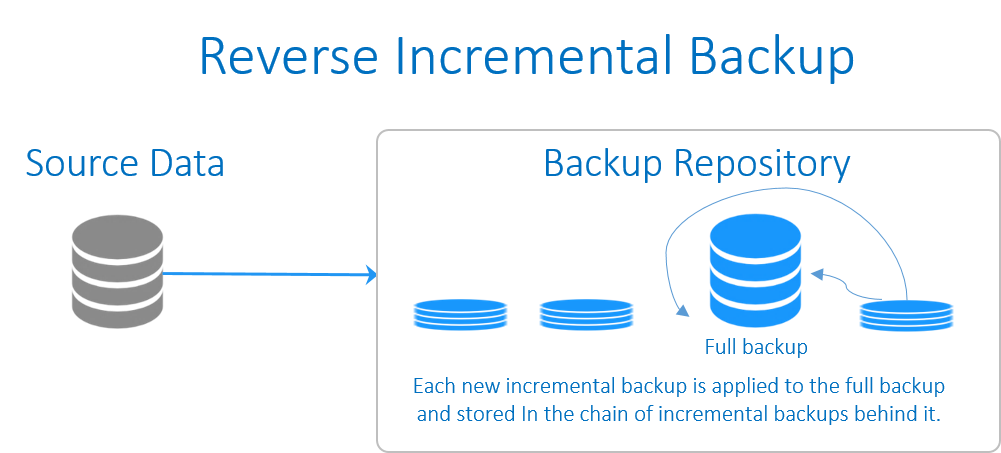
آشنایی با پروتکل DHCP
پروتکل پیکربندی پویای میزبان (به انگلیسی: Dynamic Host Configuration Protocol یا DHCP)، پروتکلی است که توسط دستگاههای شبکهای بکار میرود تا پارامترهای مختلف را که برای عملکرد برنامههای منابع گیر در IP (پروتکل اینترنت) ضروری میباشند، بدست آورد. با بکارگیری این پروتکل، حجم کار مدیریت سیستم به شدت کاهش مییابد و دستگاهها میتوانند با حداقل تنظیمات یا بدون تنظیمات دستی به شبکه افزوده شوند.
تاریخچه
DHCP برای اولین بار در اکتبر سال ۱۹۹۳ به عنوان یک پروتکل (در RFC 1531)معرفی شد. در آن زمان DHCP به منزلهٔ گسترش پروتکل Bootstrap Protocol یا (BOOTP) در نظر گرفته میشد. ایده تغییر و گسترش پروتکل BOOTP این بود که این پروتکل نیازمند یک دخالت دستی برای اضافه کردن اطلاعات هر کاربر بود. همچنین این پروتکل مکانیزمی را برای استفاده دوباره از نشانیهای IP را که استفاده نمیشوند ارائه نمیداد. این به منزله این بود که برای اتصال به اینترنت یک فرایند دستی نیاز بود. پروتکل BOOTP خودش نیز برای اولین بار در RFC951 تعریف گردید و به عنوان جایگزینی برای پروتکل RARP در نظر گفته شد. دلیل عمده جایگزینی BOOTP با RARP این بود که پروتکل RARP در لایه پیوند دادهای data link layer قرار داشت. این امر پیادهسازی و اجرا را بر روی پلتفرمهای سرور مشکل میساخت و نیازمند این بود که آن سرور در هر لایهای از شبکه پاسخگو باشد. BOOTP نوآوری بدیعی را با نام relay agent معرفی کرد. طبق آن ارسال پاکت دادهای BOOTP در شبکه با مسیریابی استاندارد IP محیا شده بود و بنابراین سرور BOOTP مرکزی میتوانست به سرویس گیرندهها (کاربران) با تعداد زیادی IP Subnet سرویس ارائه دهد.
عملی بودن
روتکل DHCP (پروتکل پیکربندی پویای میزبان) روشی برای اداره کردن جایگزینیِ پارامتر شبکه، در یک سرور DHCP مستقل، یا گروهی از چنین سرورهایی است که به شیوهای مقاوم در برابر اشکال چیده میشوند و با DHCP تکمیل شدهاند؛ حتی در شبکهای با چند ماشین سیستم DHCP مفید میباشد، زیرا یک ماشین توسط شبکهای محلی و با کمی تلاش قابل افزودن میباشد.
حتی در سرورهایی که نشانیها یشان به ندرت تغییر میکند، DHCP برای قرار دادن نشانیهای آنها توصیه میشود بنابراین اگر لازم باشد سرورها دوباره نشانیگذاری شوند (آراِف سی۲۰۷۱)، تغییرات باید در کمترین جاهای ممکن صورت گیرند. برای دستگاههایی چون مسیر یابها و دیوارهای آتش نباید DHCP را بکار بریم، عاقلانه اینست که سرورهای TFTP و SSH را در دستگاهی مشابه که DHCP را اجرا میکند قرار دهیم تا مدیریت دوباره متمرکز شود.
این پروتکل برای تخصیص مستقیم نشانیها در سرورها و سیستمهای رومیزی مفید میباشد و نیز بواسطه یک PPPپروکسی (پروتکل نقطه به نقطه) برای شمارهگیری و میزبانهای پهن باند در صورت درخواست و نیز برای خروجیها (برگردان آدرس شبکه) و مسیریابها کاربرد دارد.DHCP معمولاً برای زیر ساخت (خدمات بنیادین) مانند مسیریابهای غیر حاشیهای و سرورهای DNS مناسب نمیباشند.
هدف DHCP پیکره بندی خودکار نشانی IP یک کامپیوتر، بدون مدیر شبکه میباشد. آی پی آدرسها معمولاً از طیف وسیعی از آدرسهای اختصاص داده شده که در پایگاه داده سرور ذخیره شدهاند، تشکیل شدهاند و به کامپیوتری که درخواست یک آی پی جدید میکند، اختصاص داده میشود. یک آی پی آدرس، برای یک بازه زمانی به یک کامپیوتر اختصاص داده میشود، و پس از آن کامپیوتر باید آی پی آدرس جدیدی را از سرور دریافت کند. ممکن است کامپیوتر درخواست تمدید مهلت، یا همان افزایش زمان برای استفاده از آی پی را به سرور بفرستد و سرور درخواست افزایش زمان را رد کرده و کامپیوتر را مجبور کند تا آی پی جدیدی در فاصلهای که سپری شده درخواست کند.
غیر فنی
DHCP به کامپیوترها (کاربران) اجازه میدهد تا تنظیمات را در مدل کاربر - سرور client-server model از سرور دریافت کند.DHCP در شبکههای مدرن بسیار رایج است؛ و در شبکههای خانگی و شبکههای دانشگاهی استفاده میشود. در شبکههای خانگی، ارائه دهنده خدمات اینترنت ISP ممکن است، یک آی پی آدرس خارجی منحصربه فردرابه یک مسیر یاب Router یا مودم اختصاص دهد و این آی پی آدرس برای ارتباطات اینترنتی استفاده شود. همچنین ممکن است روتر خانگی (یا مودم) از DHCP به منظور تأمین یک آی پی آدرس قابل استفاده برای دستگاههای متصل شده به شبکه خانگی استفاده کند تا به این وسایل اجازه ارتباط با اینترنت را بدهد. آی پی آدرسهای جهانی منحصر به فردی که توسط ارائه دهنده خدمات اینترنت (ISP) اختصاص داده میشوند با آی پی آدرسهایی که به وسایل جهت اتصال به روتر خانگی داده میشود متفاوتاند. این مهم به دلیل در نظر گرفتن طرح IPv4 برای حمایت از IPv4 آدرسهااست.
فنی
DHCP تخصیص پارامترهای شبکه را به وسیله یک یا چندین سرور DHCP، به صورت اتوماتیک تبدیل میکند. حتی در شبکههای کوچک نیز DHCP مفید است، چرا که افزودن ماشینهای جدید به شبکه را آسان میکند. هنگامی که یک کاربر با پیکره بندی DHCP (یک کامپیوتر یا هر شبکه آگاه دیگر) به یک شبکه متصل میشود، کاربر یک پرسش را جهت درخواست اطلاعات لازم به سرور DHCP میفرستد. سرور DHCP یک حجم عظیم از آی پی آدرسها و اطلاعات راجع به پارامترهای پیکره بندی کاربر مانند محل عبور پیشفرض (Default Gateway) , نام دامنه، نام سرور، سرورهای دیگر مانندسرویس دهنده زمان و غیره مدیریت میشود. در دریافت یک درخواست معتبر، سرور یک آی پی آدرس، یک اجاره نامه (مدت زمانی که تخصیص معتبر است) و دیگر پارامترهای پیکره بندی آی پی مانند subnet mask ومحل عبور پیشفرض (Default Gateway) را به کامپیوتر اختصاص میدهد. پرس و جو معمولاً بلافاصله پس از راه اندازی آغاز میشود و باید تا قبل از این که کاربر بتواند ارتباطات مبتنی بر آی پی با میزبانان دیگر را آغاز کند، کامل میشود. به این ترتیب، کامپیوترهای زیادی دیگری میتوانند در مدت چند دقیقه از همان آی پی آدرس از یکدیگر استفاده کنند. از آنجا که پروتکل DHCP باید به درستی و حتی بیشتر از کاربران DHCP که پیکره بندی شدهاند کار کند، سرور DHCP و کاربر DHCP معمولاً باید به یک لینک شبکه متصل شوند. در شبکههای بزرگتر این عملی نیست. در چنین شبکههایی، هر یک از لینکهای شبکه شامل یک یا چند عامل تقویتکننده DHCP میباشند. این عوامل تقویتکننده، پیامها را از کاربران DHCP دریافت نموده و آنهارا به سرورهای DHCP انتقال میدهد. سرورهای DHCP، پاسخ را به این تقویتکنندهها میفرستند و سپس این تقویتکنندهها پاسخ را به کاربران DHCP، بر روی لینک شبکههای محلی میفرستند. بسته به نوع پیادهسازی، سرور DHCP برای تخصیص آی پی آدرس، یکی از سه روش زیر را خواهد داشت:
تخصیص پویا : مدیر شبکه محدوده خاصی از آی پی آدرسها را به DHCP اختصاص میدهد، و هر کامپیوتر کاربر که بر روی شبکه داخلی (LAN) پیکره بندی شدهاست درخواست یک آی پی آدرس را از سرور DHCP در زمان مقدار دهی اولیه ارسال میکند. فرایند درخواست و اعطا با استفاده از مفهوم اجاره نامه در یک دوره زمانی خاص قابل کنترل است، که سرور DHCP اجازه تمدید (وپس از آن تخصیص دوباره) آی پی آدرسهایی را که هماکنون تمدید نکردهاست را میدهد.
تخصیص خودکار : سرور DHCP بهطور دائم یک آی پی آدرس آزاد که توسط ادمین شبکه تعیین شدهاست را به کاربری که درخواستکننده میباشد، تخصیص میدهد. این همانند تخصیص پویاست، اما سرور DHCP یک جدول از تخصیص قبلی آی پی را نگه میدارد بهطوریکه میتواند به یک کاربر آی پی آدرسی را اختصاص دهد که قبلاً آن را داشتهاست.
تخصیص ثابت :سرور DHCP آی پی آدرسهایی مبتنی بر جدول جفت " مک آدرس / آی پی آدرس " اختصاص میدهد که این تخصیص دستی است (شاید توسط مدیر شبکه). فقط به کاربران با مک آدرسی که در لیست این جدول قرار دارند آی پی آدرس تخصیص داده خواهد شد. این ویژگی که توسط همه سرورهای DHCP پشتیبانی نمیگردد بهطور وسیعی با نام تخصیص ثابت DHCP خوانده میشود.
جزئیات تخصصی
عملکرد DHCP به چهار قسمت پایه تقسیم میگردد
- اکتشاف (DHCP Discovery)
- پیشنهاد (DHCP Offer)
- درخواست (DHCP Request)
- تصدیق (DHCP Acknowledgement)
این چهار مرحله به صورت خلاصه با عنوان DORA شناخته میشوند که هر یک از حرفها، سرحرف مراحل بالا میباشد.
DHCP Discovery (اکتشاف DHCP)
هر سرویس گیرنده (کاربر) برای شناسایی سرورهای DHCP موجود اقدام به فرستادن پیامی در زیر شبکه خود میکند. مدیرهای شبکه میتوانند مسیریاب محلی را به گونه ایی پیکربندی کنند که بتواند بسته دادهای DHCP را به یک سرور DHCP دیگر که در زیر شبکه متفاوتی وجود دارد، بفرستد. این مهم باعث ایجاد بسته داده با پروتکل UDP میشود که آدرس مقصد ارسالی آن ۲۵۵٫۲۵۵٫۲۵۵٫۲۵۵ یا آدرس مشخص ارسال زیر شبکه میباشد. کاربر (سرویس گیرنده) DHCP همچنین میتواند آخرین آی پی آدرس شناخته شده خود را درخواست بدهد. اگر سرویس گیرنده همچنان به شبکه متصل باشد در این صورت آی پی آدرس معتبر میباشد و سرور ممکن است که درخواست را بپذیرد. در غیر اینصورت، این امر بستگی به این دارد که سرور به عنوان یک مرجع معتبر باشد. یک سرور به عنوان یک مرجع معتبر درخواست فوق را نمیپذیرد و سرویس گیرنده را مجبور میکند تا برای درخواست آی پی جدید عمل کند. یک سرور به عنوان یک مرجع غیرمعتبر به سادگی درخواست را نمیپذیرد و آن را به مثابهٔ یک درخواست پیادهسازی از دست رفته تلقی میکند؛ و از سرویس گیرنده میخواهد درخواست را لغو و یک آی پی آدرس جدید درخواست کند.
DHCP Offer (پیشنهاد DHCP)
زمانی که یک سرور DHCP یک درخواست را از سرویس گیرنده (کاربر) دریافت میکند، یک آی پی آدرس را برای سرویس گیرنده رزرو میکند و آن را با نام DHCP Offer برای کاربر میفرستد. این پیام شامل: MAC آدرس (آدرس فیزیکی دستگاه) کاربر؛ آی پی آدرسی پیشنهادی توسط سرور؛ Subnet Mask آی پی؛ زمان تخصیص آی پی (lease Duration) و آی پی آدرس سروری میباشد که پیشنهاد را دادهاست.
DHCP Request (درخواست DHCP)
سرویس گیرنده با یک درخواست به مرحله پیشین پاسخ میگوید. یک کاربر میتواند پیشنهادهایهای مختلفی از سرورهای متفاوت دریافت کند. اما فقط میتواند یکی از پیشنهادها را بپذیرد. بر اساس تنظیمات شناسایی سرور در درخواست و فرستادن پیامها (identification option)، سرورها مطلع میشوند که پیشنهاد کدام یک پذیرفته شدهاست. هنگامی که سرورهای DHCP دیگر این پیام را دریافت میکنند، آنها پیشنهادهای دیگر را، که ممکن است به کاربر فرستاده باشند، باز پس میگیرند و آنها را در مجموعه آی پیهای در دسترس قرار میدهند.
DHCP Acknowledgement (تصدیق DHCP)
هنگامی که سرور DHCP، پیام درخواست DHCP را دریافت میکند، مراحل پیکربندی به فاز پایانی میرسد. مرحله تصدیق شامل فرستادن یک بسته دادهای (DHCP Pack) به کاربر میباشد. این داده بستهای شامل: زمان تخصیص آی پی یا هرگونه اطلاعات پیکربندی که ممکن بودهاست که سرویس گیرنده درخواست کرده باشد، میباشد. در این مرحله فرایند پیکربندی آی پی کامل شدهاست.
ساختار پیامهای DHCP
پیغامهای DHCP در دیتا گرامهای UDP حمل میشوند و در سمت سرویس دهنده از شماره پورت ۶۷ و در سمت سرویس گیرنده از پورت ۶۸ استفاده میکند. پروتکلهایی که در ارتباط با DHCP کار میکنند شامل IP, BOOTP , UDP, TCP, RARP میباشند. در جدول زیر ساختار پروتکل DHCP را مشاهده مینمایید.[۱]
| OP | HTYPE | HLEN | HOPS |
| TRANSACTION ID | |||
| SECS | FLAGS | ||
| CIADDR (Client IP address) | |||
| YIADDR (Your IP address) | |||
| SIADDR (Server IP address) | |||
| GIADDR (Gateway IP address) | |||
| CHADDR (Client hardware address (16 OCTETS)) | |||
| SERVER HOST NAME (64 OCTETS) | |||
| BOOT FILE NAME (128 OCTETS) | |||
| OPTIONS (VARIABLE) | |||
- Operation Code: اختصاص یافته به پیام که میتواند BOOTREQUEST یا BOOTREPLY باشد به عبارتی دیگر مشخص میکند که پیام از سرویس دهنده تولید شدهاست یا سرویس گیرنده و اندازه این پیام همانطور که در جدول هم مشاهده میشود 8bit که معادل یک بایت است.
- HTYPE: نوع آدرس سختافزاری موجود در فیلد chaddr را مشخص میکند و اندازه آن هم یک بایت است.
- Hlen: طول آدرس سختافزاری موجود در فیلد Chaddr را بر حسب بایت نشان میدهد.
- Hops: تعداد مسیریابهای موجود بین سرور و سرویس گیرنده را مشخص میکند و اندازه آن یک بایت است.
- Xid یا Transaction ID: حاوی یک شناسه برای نسبت دادن جوابها به درخواستها میباشد و به نوعی کد متعلق به فرایند اختصاص یافته بین یرویس دهنده و سرویس گیرنده میباشد و چهار بایت است.
- Secs: مدت گذشته از زمان شروع یک تخصیص آدرس یا فرایند تمدید اجاره را مشخص میکند و ۲ بایت حجم آن است.
- Flags: یا بیت پرچم که دو بایت است و مشخص میکند که سرورهای DHCP و واسطهای رلهکننده باید برای ارتباط با یک سرویس گیرنده به جای انتقال تک پخشی از انتقال با پخش همگانی استفاده کنند یا خیر و ۲ بایت است.
- CIADDR: آدرس IP سرویس گیرنده به عبارت دیگر آدرس IP کامپیوتر زمانی که در وضعیت باند، تمدید اجاره IP یا ارتباط مجدد میباشد را دارا است و اندازه آن چهار بایت است.
- YIADDR: آدرس IP سرویس گیرنده شما به عبارت دیگر آدرس IP که توسط DHCP به یک کامپیوتر واگزار شدهاست را دربردارد و اندازه آن چهار بایت است.
- SIADDR: آدرس IP سرور بعدی را در یک دنباله Bootstrap مشخص میکند از این مقدار فقط زمانی که سرور DHCP یک فایل راه انداز اجرایی به یک سرویس گیرنده بدون دیسک میدهد استفاده میشود و اندازه آن ۴ بایت است.
- GIADDR: در صورت نیاز، حاوی آدرس IP یک واسط رلهکننده DHCP مستقر روی شبکهای دیگر میباشد و اندازه آن ۴ بایت است.
- CHADDR: آدرس سختافزاری سرویس گیرنده یا به عبارتی دیگر، با استفاده از نوع و اندازهای که در فیلدهای htype و hlen مشخص شدهاست نشان دهنده آدرس سختافزاری سرویس گیرنده میباشد؛ و مقدار آن ۱۶ بایت است.
- SERVER HOST NAME که یا حاوی نام DHCP server است یا حاوی دادههای سر ریز فیلد option میباشد؛ و مقدار آن ۶۴ بایت است.
- BOOT FILE NAME: شامل نام فایل boot، یک رشته خاتمه دهنده تهی، نام عمومی یا یک رشته تهی در DHCPDISCOVER، یک fully qualified directory-path name در DHCPOFFER است و به عبارتی برای clientهای بدون دیسک حاوی نام و آدرس یک فایل راه انداز اجرایی میباشد و ۱۲۸ بایت است.
- Option: فیلد پارامترهای اختیاری و به نوعی حاوی مجموعهای از گزینههای DHCP میباشد که مشخصکننده پارامترهای پیکربندی کامپیوتر سرویس گیرنده هستند.
منبع : ویکی پدیا
برچسب ها : آشنایی با پروتکل DHCP, پروتکل DHCP,